Metagenome Annotation Workflow (v1.0.0)
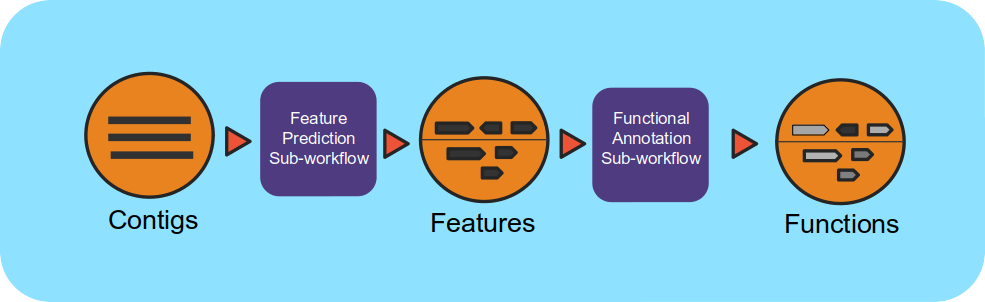
Workflow Overview
This workflow takes assembled metagenomes and generates structural and functional annotations. The workflow uses a number of open-source tools and databases to generate the structural and functional annotations.
The input assembly is first split into 10MB splits to be processed in parallel. Depending on the workflow engine configuration, the split can be processed in parallel. Each split is first structurally annotated, then those results are used for the functional annotation. The structural annotation uses tRNAscan_se, RFAM, CRT, Prodigal and GeneMarkS. These results are merged to create a consensus structural annotation. The resulting GFF is the input for functional annotation which uses multiple protein family databases (SMART, COG, TIGRFAM, SUPERFAMILY, Pfam and Cath-FunFam) along with custom HMM models. The functional predictions are created using Last and HMM. These annotations are also merged into a consensus GFF file. Finally, the respective split annotations are merged together to generate a single structural annotation file and single functional annotation file. In addition, several summary files are generated in TSV format.
Workflow Availability
The workflow is available in GitHub: https://github.com/microbiomedata/mg_annotation/ and the corresponding Docker image is available in DockerHub: https://hub.docker.com/r/microbiomedata/mg-annotation.
Requirements for Execution (recommendations are in bold):
WDL-capable Workflow Execution Tool (Cromwell)
Container Runtime that can load Docker images (Docker v2.1.0.3 or higher)
Hardware Requirements:
Disk space: 106 GB for the reference databases
Memory: >100 GB RAM
Workflow Dependencies
- Third party software (This is included in the Docker image.)
Conda (3-clause BSD)
tRNAscan-SE >= 2.0 (GNU GPL v3)
Infernal 1.1.2 (BSD)
CRT-CLI 1.8 (Public domain software, last official version is 1.2)
Prodigal 2.6.3 (GNU GPL v3)
GeneMarkS-2 >= 1.07 (Academic license for GeneMark family software)
Last >= 983 (GNU GPL v3)
HMMER 3.1b2 (3-clause BSD)
TMHMM 2.0 (Academic)
Requisite databases: The databases are available by request. Please contact NMDC (support@microbiomedata.org) for access.
Sample datasets
https://raw.githubusercontent.com/microbiomedata/mg_annotation/master/example.fasta
Input: A JSON file containing the following:
The path to the assembled contigs fasta file
The ID to associate with the result products (e.g. sample ID)
An example JSON file is shown below:
{
"annotation.imgap_input_fasta": "/path/to/fasta.fna",
"annotation.imgap_project_id": "samp_xyz123"}
}
Output: The final structural and functional annotation files are in GFF format and the summary files are in TSV format. The key outputs are listed below but additional files are available.
GFF: Structural annotation
GFF: Functional annotation
TSV: KO Summary
TSV: EC Summary
TSV: Gene Phylogeny Summar
The output paths can be obtained from the output metadata file from the Cromwell Exectuion. Here is a snippet from the outputs section of the full metadata JSON file.
{
"annotation.cath_funfam_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_cath_funfam.gff",
"annotation.cog_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_cog.gff",
"annotation.ko_ec_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_ko_ec.gff",
"annotation.product_names_tsv": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_product_names.tsv",
"annotation.gene_phylogeny_tsv": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_gene_phylogeny.tsv",
"annotation.pfam_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_pfam.gff",
"annotation.proteins_tigrfam_domtblout": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_proteins.tigrfam.domtblout",
"annotation.structural_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_structural_annotation.gff",
"annotation.ec_tsv": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_ec.tsv",
"annotation.supfam_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_supfam.gff",
"annotation.proteins_supfam_domtblout": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_proteins.supfam.domtblout",
"annotation.tigrfam_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_tigrfam.gff",
"annotation.stats_tsv": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-final_stats/execution/samp_xyz123_structural_annotation_stats.tsv",
"annotation.proteins_cog_domtblout": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_proteins.cog.domtblout",
"annotation.ko_tsv": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_ko.tsv",
"annotation.proteins_pfam_domtblout": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_proteins.pfam.domtblout",
"annotation.proteins_smart_domtblout": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_proteins.smart.domtblout",
"annotation.crt_crisprs": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_crt.crisprs",
"annotation.functional_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_functional_annotation.gff",
"annotation.proteins_faa": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123.faa",
"annotation.smart_gff": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_smart.gff",
"annotation.proteins_cath_funfam_domtblout": "/output/cromwell-executions/annotation/a67a5a0f-1ad7-4469-bb0c-780f4ef20307/call-merge_outputs/execution/samp_xyz123_proteins.cath_funfam.domtblout"
}
Version History: 1.0.0 (release data)
Point of contact
Package maintainer: Shane Canon <scanon@lbl.gov>